机器学习
从经典算法到工程实践——理解数据驱动建模的核心方法论,面试中从容应对 ML 基础问题。
机器学习是让计算机从数据中学习规律、做出预测或决策的技术。不同于传统编程"人写规则",ML 是"数据生成规则"。
学习路线
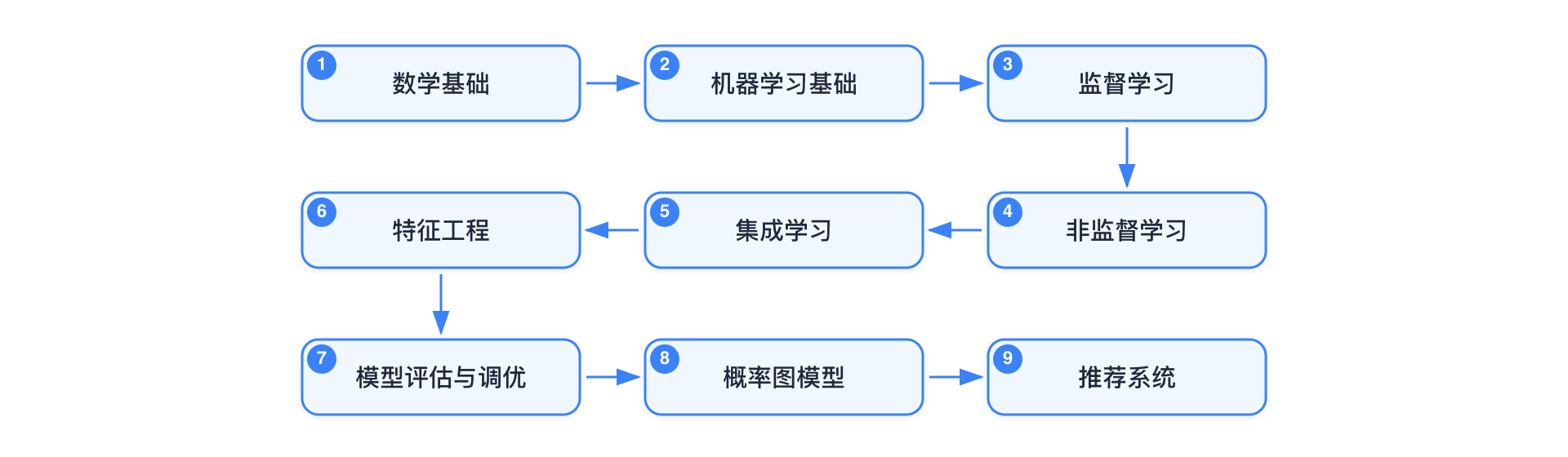
内容导航
| 主题 | 核心内容 | 面试重点 |
|---|---|---|
| 数学基础 | 线性代数、概率统计、微积分、信息论 | 矩阵运算、贝叶斯定理、梯度与优化 |
| 机器学习基础 | 三大学习类型、过拟合/欠拟合、偏差方差、数据集划分、评估指标 | 过拟合解决方案、精确率vs召回率 |
| 监督学习 | 线性回归、逻辑回归、SVM、决策树、KNN | 损失函数推导、正则化、核函数 |
| 非监督学习 | K-Means、DBSCAN、PCA、t-SNE | 聚类评估指标、降维原理 |
| 集成学习 | Bagging、Random Forest、AdaBoost、XGBoost、LightGBM | Boosting vs Bagging、GBDT 原理 |
| 特征工程 | 特征选择、特征构造、编码方式、归一化 | 类别特征处理、特征重要性 |
| 模型评估与调优 | 交叉验证、Precision/Recall/F1、AUC-ROC、超参搜索 | 过拟合与欠拟合、偏差方差权衡 |
| 概率图模型 | 朴素贝叶斯、贝叶斯网络、HMM、CRF | 条件独立性、EM 算法 |
| 推荐系统 | 协同过滤、矩阵分解、召回-粗排-精排-重排 | 冷启动问题、推荐链路设计 |
面试高频考点
必须掌握的核心问题
- 偏差与方差的权衡:模型复杂度如何影响泛化能力
- 过拟合的原因与解决方案:正则化、Dropout、Early Stopping、数据增强
- 梯度下降的变体:BGD vs SGD vs Mini-batch,Adam 为什么好用
- 树模型 vs 线性模型:各自的适用场景和优缺点
- 评估指标的选择:什么时候用 AUC,什么时候用 F1,为什么不能只看 Accuracy
与深度学习的关系
| 维度 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征工程 | 需要手工设计特征 | 自动学习特征表示 |
| 数据需求 | 小数据也能工作 | 需要大量数据 |
| 可解释性 | 较强(决策树、线性模型) | 较弱(黑盒) |
| 计算资源 | CPU 即可 | 通常需要 GPU |
| 适用场景 | 结构化数据、表格数据 | 图像、文本、语音等非结构化数据 |
面试误区
不要认为"深度学习取代了机器学习"。在结构化数据(表格)场景中,XGBoost / LightGBM 等传统模型依然是首选,Kaggle 竞赛中表格数据的冠军方案绝大多数使用树模型。